All the methods developed for Human Activity Recognition are for data from conventional cameras where there is a lot of information in every frame. In this project, we perform Human Activity Recognition for data from event camera called Dynamic Vision Sensors, which record only the change in pixel intensity values. We propose new feature descriptors called the Motion Maps in order to increase the accuracy on event data to that reported on conventional frame based data. For a better understanding of dynamic vision sensors, we recommend watching this video.
Abstract
Unlike conventional cameras which capture video at a fixed frame rate, Dynamic Vision Sensors (DVS) record only changes in pixel intensity values. The output of DVS is simply a stream of discrete ON/OFF events based on the polarity of change in its pixel values. DVS has many attractive features such as low power consumption, high temporal resolution, high dynamic range and less storage requirements. All these make DVS a very promising camera for potential applications in wearable platforms where power consumption is a major concern. In this paper we explore the feasibility of using DVS for Human Activity Recognition (HAR). We propose to use the various slices (such as $x − y$, $x − t$ and $y − t$) of the DVS video as a feature map for HAR and denote them as Motion Maps. We show that fusing motion maps with Motion Boundary Histogram (MBH) gives good performance on the benchmark DVS dataset as well as on a real DVS gesture dataset collected by us. Interestingly, the performance of DVS is comparable to that of conventional videos although DVS captures only sparse motion information.
Motion Maps
We first convert DVS event streams into a video by accumulating events over a time window. For our experiments we made videos at $30fps$ framerate. From this, we obtain different $2$-D projections: $x − y$, $x − t$ and $y − t$ by averaging over each left-out dimension. Thus, $x − y$ projection is obtained by averaging over the $time$ axis, $x − t$ averages $y − axis$ and $y − t$ by averages $x − axis$. We call these $2$-D projections as motion maps.
(a) $x − y$ Motion Map
(b) $x − t$ Motion Map
(c) $y − t$ Motion Map
Figure 1: The three Motion Maps for 11 randomly picked UCF11 videos.
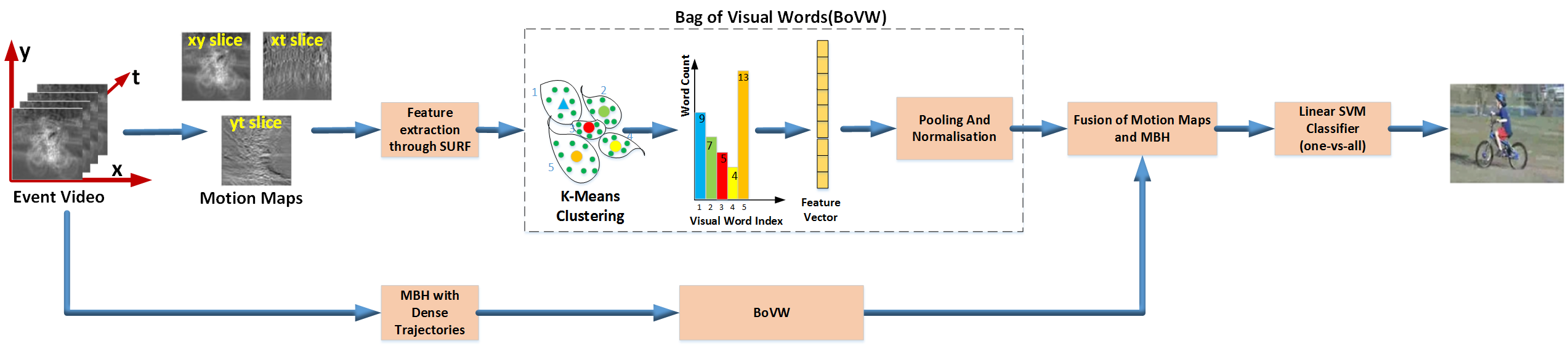
Our proposed architecture
Motion maps are generated through various projections of this event video and SURF features are extracted. MBH features using dense trajectory are also extracted. Bag of features encoding from both these descriptors are combined and given to linear SVM classifier (one-vs-all).
Figure 2: Our proposed architecture.
Experiments
We have performed the experiments with the proposed architecture on the DVS recording of the UCF11 dataset as well as the DVS gesture dataset collected by us. We could achieve $98.8\%$ accuracy on our gesture dataset.
(b) UCF11 dataset
(b) DVS gesture dataset collected by us
Figure 3: The datasets we conducted our experiments on. We compared the accuracies of our proposed method on the original UCF11 and the DVS recordings of it.